
Single-Row Deadlock
Introduction
Demonstration of the smallest possible deadlock: only one statement, one table, one row.
Without transactions (no BEGIN TRANSACTION). Even RCSI (Read Committed Snapshot Isolation) is turned ON to eliminate shared locks. Everything is “by the book” as Books Online suggest to minimize deadlocks. How is that possible to deadlock? There is a complexity in simplicity of this demo. In video it is explained why single-row deadlock occurs. If you understand single-row deadlock, you will be able to understand even most complex production deadlock situations. And understanding the cause is the first step to eliminate them.
Enjoy the video, and tell me your opinion. Thank you!

What statement deadlocks?
Believe it or not, these two statements will deadlock:
|
1 2 3 4 5 6 7 |
-- SESSION A UPDATE t SET t.Data = GETDATE(), t.SomeValue = 1 FROM dbo.Deadlock t WHERE t.Id = 1 -- SESSION B UPDATE t SET t.Data = GETDATE(), t.SomeValue = 1 FROM dbo.Deadlock t WHERE t.SomeValue = 1 |
Those will deadlock, even though:
- it is only ONE statement per session (not usual example with two SQL commands within BEGIN TRAN .. COMMIT block)
- they touch only ONE table
- they touch only ONE row (and both sessions touch the same row)
- we do not have (explicit) transactions, just “normal” commands (BEGIN TRAN/COMMIT is not there at all!)
There are three deadlock examples in the demo, this is only the first one. In case you wonder, demo is recorded on SQL Server 2017, but the same is on any version so far, and probably with any other RDBMS that uses locks. Same effect could be shown using eg. Oracle. The beauty is to understand it and armed with that knowledge, eliminate the deadlocks in production or at least greatly reduce them.
Why “WHILE” Loop?
In the demo, you will notice that I add this at start of each session’s command:
|
1 2 |
SET NOCOUNT ON WHILE 1=1 |
Why? Because deadlock is a racing condition. It does not happen every time.
Deadlock will happen only if we hit the “right” moment to execute other session in relation to first session. To achieve that, I run the command in a loop waiting for that special moment to hit after certain number of loop iterations. Because on each iteration session’s relation to each other will move a tiny bit, until the “right” moment is hit and deadlock occurs. The same reason is why in your production environment you see deadlocks only occasionally, and often you cannot reproduce it, at least not easily.
The explanation
There is no “row” lock. In reality, what is locked is a 6-byte hash calculated from index’s KEY value of that row. For example, we have 2 indexes on that table: clustered which has “Id” column as index key, and non-clustered which has column “SomeValue” as index key. That hashed value of the index key can be seen using %%lockres%% function:
|
1 2 |
SELECT hash_of_CL_key = %%lockres%%, * FROM dbo.Deadlock d WITH(INDEX(PK_CL_Deadlock)) SELECT hash_of_NC_key = %%lockres%%, * FROM dbo.Deadlock d WITH(INDEX(NC_IX_Deadlock)) |
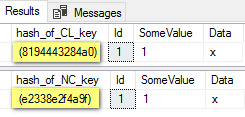
Therefore, for the same row (row with Id=1), we have 2 indexes and X-locking 2 different hash values. And two locks are locked in order, not at the same time. If one session first locks first hash then second hash, and the other session first locks second hash then first hash, it is possible to create a deadlock “circle” between them if we hit the right moment. That depends on execution plan, with which index will it access the table first.
Hash collision
By the way, hash values can “collide”, that is, for different input value give same output value. That happens with all hash functions, even with hashing function that is used by locking algorithm. More rows locked, higher probability of collision. For example, if you have a large transaction that insert rows in the table, and some other session does the same, it is likely they will occasionally block even they never insert the same row values. Eg each insert command inserts 1 000 000 000 rows and normally takes 4h. Occasionally, insert takes 8h, because session is blocked by other session and waits 4h until first one is finished, although they are inserting different values for sure (enforced by app logic). Execution times are 4h, 4h, 8h, 4h, 4h, 8h, etc. But that is a topic for a new blog post.
The Setup
Creating a database and a table for the demo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
--------------------------------------------------- -- SETUP: Create database --==>>> Create TestDatabase USE master IF DATABASEPROPERTYEX('TestDatabase', 'STATUS') IS NOT NULL BEGIN ALTER DATABASE TestDatabase SET SINGLE_USER WITH ROLLBACK IMMEDIATE; DROP DATABASE TestDatabase; END GO CREATE DATABASE TestDatabase; GO ALTER DATABASE TestDatabase SET RECOVERY SIMPLE ALTER DATABASE TestDatabase SET READ_COMMITTED_SNAPSHOT ON ALTER DATABASE TestDatabase SET ALLOW_SNAPSHOT_ISOLATION ON GO -- SETUP: Clustered table with single NC index USE TestDatabase GO IF object_id('dbo.Deadlock') IS NOT NULL DROP TABLE dbo.Deadlock; CREATE TABLE dbo.Deadlock(Id INT IDENTITY CONSTRAINT PK_CL_Deadlock PRIMARY KEY CLUSTERED, SomeValue INT DEFAULT 0, Data CHAR(6000) DEFAULT 'x'); CREATE INDEX NC_IX_Deadlock ON dbo.Deadlock(SomeValue) INCLUDE(Data) GO SET NOCOUNT ON INSERT INTO dbo.Deadlock(SomeValue) VALUES (1); GO INSERT INTO dbo.Deadlock DEFAULT VALUES; GO 1000 SELECT * FROM dbo.Deadlock d ORDER BY Id |
3 Deadlock Examples
You can run examples from the video yourself:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
---------------------------- -- Single row, will deadlock after about 1 minute -- SESSION A SET NOCOUNT ON WHILE 1=1 UPDATE t SET t.Data = GETDATE(), t.SomeValue = 1 FROM dbo.Deadlock t WHERE t.Id = 1 -- SESSION B SET NOCOUNT ON WHILE 1=1 UPDATE t SET t.Data = GETDATE(), t.SomeValue = 1 FROM dbo.Deadlock t WHERE t.SomeValue = 1 ---------------------------- -- Single statement, will deadlock after about 5 seconds -- SESSION A: Lock the CL row. Consequently that locks NC row. SET NOCOUNT ON DECLARE @SomeValue INT = 1, @Data CHAR(1)='a' WHILE 1=1 UPDATE t SET t.Data = @Data, t.SomeValue = 1 FROM dbo.Deadlock t WHERE t.SomeValue = @SomeValue OPTION(OPTIMIZE FOR UNKNOWN) -- SESSION B: Lock the NC row. Consequently, that locks the CL row. SET NOCOUNT ON DECLARE @SomeValue INT = 1, @Data CHAR(1)='b' WHILE 1=1 UPDATE t SET t.Data = @Data, t.SomeValue = 1 FROM dbo.Deadlock t WHERE t.SomeValue = @SomeValue OPTION(OPTIMIZE FOR(@SomeValue=0)) -------------------------------------------------- -- Single-index (Clustered) table, 2 rows - deadlocks after 2 seconds -------------------------------------------------- USE TestDatabase GO IF object_id('dbo.Deadlock') IS NOT NULL DROP TABLE dbo.Deadlock; CREATE TABLE dbo.Deadlock(Id INT IDENTITY CONSTRAINT PK_CL_Deadlock PRIMARY KEY CLUSTERED,SomeValue INT DEFAULT 0, Data CHAR(6000) DEFAULT 'x'); GO INSERT INTO dbo.Deadlock DEFAULT VALUES; GO 2 -- 2 rows only! -- SESSION A: Lock the CL row SET NOCOUNT ON WHILE 1=1 UPDATE t SET t.SomeValue = 1 FROM ( SELECT TOP 2 * FROM dbo.Deadlock t ORDER BY t.Id ASC ) t -- SESSION B: Lock the CL row. but in different order. SET NOCOUNT ON WHILE 1=1 UPDATE t SET t.SomeValue = 1 FROM ( SELECT TOP 2 * FROM dbo.Deadlock t ORDER BY t.Id DESC ) t |
Summary
It is possible deadlock will occur between two ordinary DML commands, without BEGIN TRAN/COMMIT block. Some showed that it can occur between two rows, but here is demonstrated It can occur even when they lock the same, single row, as long as table has more than one index. Even on a table with only one index, deadlock can occur if it has more than 1 row, because we again have at least 2 hashes to lock and now all depends on order we lock them. Since almost every databases has more than 1 row in total, deadlock can occur in any database.
The challenge:
Produce a deadlock in a database without any rows! 🙂
What is the solution to solving the one row deadlock above ?
Thanks for the question! First of all, one row deadlock is very unlikely to happen in reality. It is a racing condition, we need to “hit” the right moment, that is why I am using an indefinite loop to eventually hit the “right” moment. In reality, probability to hit this kind of deadlock is very low. But – we can decrease that probability (aka “solve” this kind of deadlock) by enabling RCSI to eliminate locks of readers, drop unused indexes, merge similar indexes (decrease num of indexes so lock duration is shorter), and making sure all change operations (ins/upd/del) use the same index. Eg, one could first find the rows to update/del by name/date indexes or whatever he needs, store ID into temp table, and then use the stored PK from temp table to update/del the table – that guarantees always the same order, and no closed lock loop (deadlock) can happen.
Yeah, I have seen a weird one recently where this actually has happened in a very large OLTP system. My own feeling is that a simple UPDLOCK should fix this but I’m can’t reproduce it locally like you have – it ran for hours with over 10 million updates and no deadlocks on their UAT systems.
One table, single row…
SET NOCOUNT ON;
DECLARE @NewNumber INT;
UPDATE dbo.NextNum
SET @NewNumber = NextNumber,
NextNumber = @NewNumber + 1;
Is it a heap or a clustered index table? Does it have any non-clustered indexes? Ideally, it should have only one index – clustered index.
Is this UPDATE a part of a bigger transaction? Ideally, it should not be.
For this purpose, a SEQUENCE object might be better to use instead of this table. That would avoid the deadlock. If still in trouble, contact me via PM/email and I will solve this problem on that server. I own a consulting company specialized in SQL Server databases and help many clients worldwide improving their database systems.