
How to partition a really big table?
Introduction
For one customer I just transferred a troubled 2TB table (2 billion rows) into a monthly-partitioned table in just 2.5 hours and no downtime! To make things more difficult, within that time additional deduplication had to be performed, as table had duplicates caused by an app bug. No helpful indexes existed nor could be created (any index create was impossible, fails after several weeks of runtime). Previous DBA attempt estimated 3 months to move these rows (he used the “normal” way and failed). It was SQL 2019 Enterprise Edition hosted on a big Azure VM using Storage Spaces array of disks for fast storage access.
What does NOT work?
Let’s say we try to move rows using a neat DELETE-OUTPUT command, which can delete from original and insert into destination table at the same time. That has to write 2TB of transaction log for insert and another 2TB of transaction log for delete. Writing 4TB of transaction log would take ages. We will use something else.
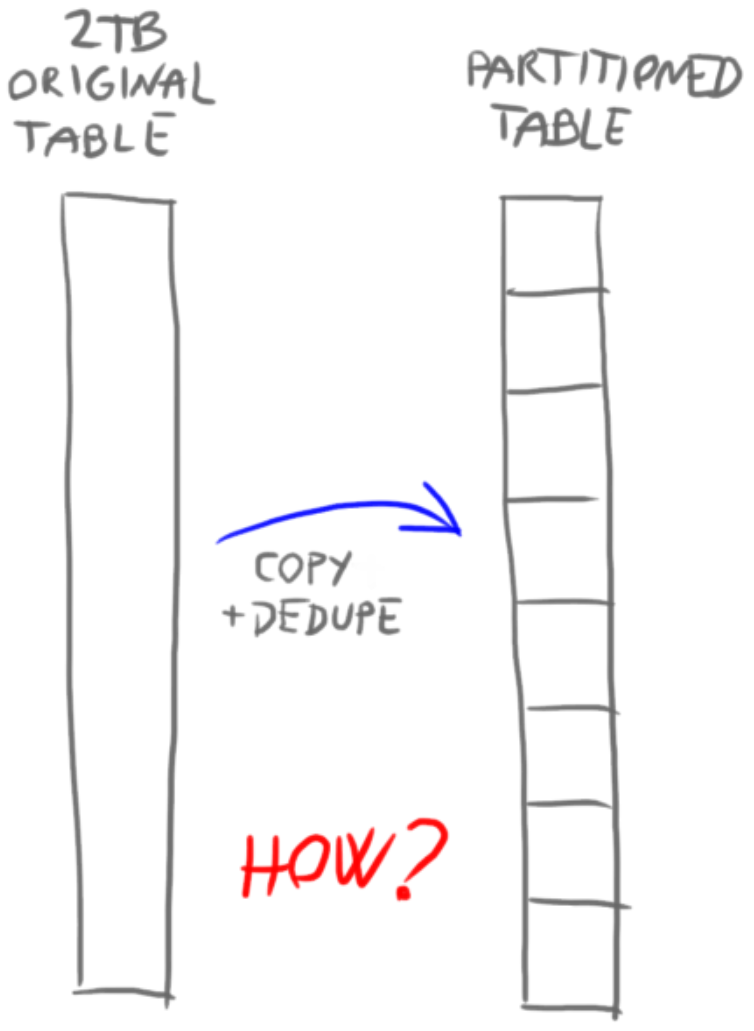
Phase 1 – copy to _TEMP
We need a way to copy and deduplicate all rows into a new partitioned table, as fast as possible. To do it efficiently, we must scan the CLUSTERED index (CL). In our case, CL key was ever-increasing identity that only partially correlates to time-related column (our future partition key). If we used any non-clustered index, even „ideal“ one, the execution plan would contain a „key lookup“ operator, because not all columns are there in the NC. That adds additional 3-5 logical reads per row, resulting in around 300x slower read time. Instead of 2h it would take almost one month! That is why we stick to whatever CL index we have there. I can elaborate, but that is out of scope for this post (ask in comments).
To use the power of many available CPU cores, we have to run in multiple threads. We want to make CPU busy so this process finishes faster. We will split the workload into ranges of CL key. Each range is calculated based on number of threads and min and max value of the CL key. A single stored procedure will run this entire phase. Multiple SQL agent jobs will call that proc in parallel, from multiple sessions, but with different input range values (@StartId, @EndId). We will use 6 jobs (6 threads).
We want to avoid long transactions because we want to prevent excessive transaction log growth and more important, to limit RAM need of sort operation. Also, we want to avoid small transactions. Especially one-by-one row processing (RBAR, row-by-agonizing-row), because RBAR is the slowest and the most inefficient way to process anything. And yet, that slowest possible implementation is the most common I can see in the field. I guess due the lack of knowledge on how to do set processing instead of row processing. We hold the middle ground and grab data in batches of 300 000 rows. The WHERE filter on CL key looks like this: WHERE Id BETWEEN @startID AND @startID + @batchSize – 1. That allows us to skip the TOP clause. We also skip any temp tables and table variables – we do NOT store IDs. That extra work of storing IDs would make things much slower. After INSERT-SELECT we increase the start with SET @start += @batchSize. Small caveat: we need to make sure we do not pass max Id of the given range by adjusting the @batchSize in the last iteration.
Destination table is empty, partitioned by month, but in a separate filegroup. During import it has only one index: clustered index. If it would be a heap, loading it would be faster, but total time to load + create CL index would be slower than loading a table which already has a CL index. NC indexes on the other hand would make the load much slower, so we create them later, with a special trick.
How to solve deduplication? Definition: „Duplicate“ has all column values identical except Id (identity). Deleting duplicates would be super-slow, as delete (besides UPDATE) is one of the slowest operations in SQL server. Much faster is to skip duplicates on copy by using SELECT with combination of ROW_NUMBER() OVER() analytic function to copy only 1 row per each set of duplicate rows. We copy in batches which means it is a partial deduplication, within each batch. Global deduplication has to be done later. To deduplicate, a SORT operator in execution plan is unavoidable here. Sort operator is really bad. It takes memory and CPU, makes things go slower. But, that sacrifice we cannot avoid here, and will be awarded with 40% less rows being copied. Deduplication is only partial, but most of duplicates are removed in this step and only a small percentage of duplicates is left to cleanup alter. Reducing gigabytes early matters!
Fine tuning memory: When the copy process started I noticed a high activity in tempdb. That means SORT operation spilled to tempdb because SQL has estimated and allocated too small amount of RAM for the sort operation. Spill to tempdb makes our reading of data super-slow, similar to working with page file instead of RAM. Adding hint OPTION(MIN_GRANT_PERCENT=90, MAX_GRANT_PERCENT=90) removed tempdb usage, but added a different issue: now threads were blocked with RESOURCE_SEMAPHORE wait! That wait means command wants to allocate an amount of RAM which is not yet available, so the thread has to wait. And waiting is something we want to avoid. Reducing the MAX_GRANT_PERCENT hint will remove that issue, but if I reduce too much I will go again into heavy tempdb usage, so we need to find something in between. And that was 70% in my case. Without the hint, SQL 2019 will dynamically auto-adjust memory alocation, but it just does a ping-pong between tempdb contention and RESOURCE_SEMAPHORE waits, allocating too small or too big amount every time resulting in slower performance. Hint set to 70% proved to be the sweet spot in my case, removing RESOURCE_SEMAPHORE waits while still no tempdb spills. Your ideal numbers might be different.
Fine tuning statistics: at database level auto-statistics refresh is set to by asynchronous. That means in a separate, background thread so our (user) threads won’t wait for stats. Every partitioned table lock escalation we changed to „auto“ which allows partitions to be locked instead of entire table. That is really important. Also, all statistics tied to indexes on all partitioned tables are changed to be „incremental“, which means partition-level statistics. That makes them easier and faster to update, as well as more precise.
Fine-tuned as described, and using 6 threads, each calling exactly the same stored procedure named CopyToTemp, it took only 30min to partially deduplicate and copy 2 billion rows in this phase – amazing!
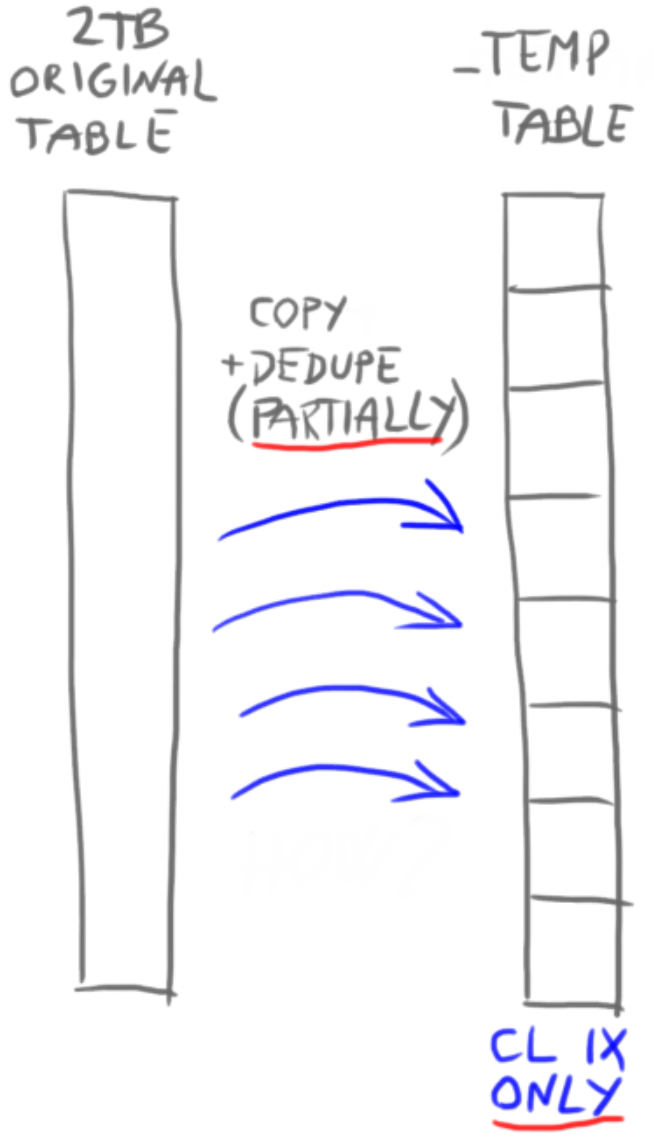
Phase 2 – copy to guest
After phase 1 finished, we have data partitioned by month, residing in a new filegroup, but we do not have NC indexes and we still have some duplicates. We want to remove duplicates before creating NC indexes, so less rows enter indexes (minify GB as early as possible). This time we do deduplication via DELETE command. Looks bad but is perfectly fine here, because only a small percentage of duplicates live in this phase because we already removed majority of them in phase 1. Deleting a small amount of rows is quite fast. All the code of phase two is in a 2nd stored procedure called CopyToGuest. This time input range is time-based instead of identity-based, by month of the partitioning key column. Another 6 SQL Agent jobs (threads) are created, calling the CopyToGuest procedure with different range values. Deduplication here is global and complete. Although we deduplicate only within each partition (month), because partitions are not overlapping it a global deduplication and in total we removed 44% of starting rows.
To create NC indexes we will leverage SWITCH PARTITION technique. SWITCH is a super-fast, metadata operation that instantly assigns rows of one object to another, with some limitations. Two tables can switch places, not just two partitions, and also table and partition can switch places. Any combination works as long as they have the same schema, filegroup, indexes, and the switch destination has no rows. First we switch rows from the source partition (month) into a stage table. We use multiple stage tables, one per thread/job. Inside the stage table we perform described deduplication using DELETE and ROW_NUMBER() OVER(). Then we build NC indexes and switch stage table into a final partitioned table. CHECK constraint on partitioning key column had to be created as that was a prerequisite for that final switch, otherwise it fails with error that some rows may be outside of the partition range.
Both procedures, CopyToTemp and CopyToGuest are built to continue where they left off if anything stops them. That is achieved by checking what is in destination, and continuing from there. So, there is no extra saving „progress“ anywhere, destination table is our indicator of progress.
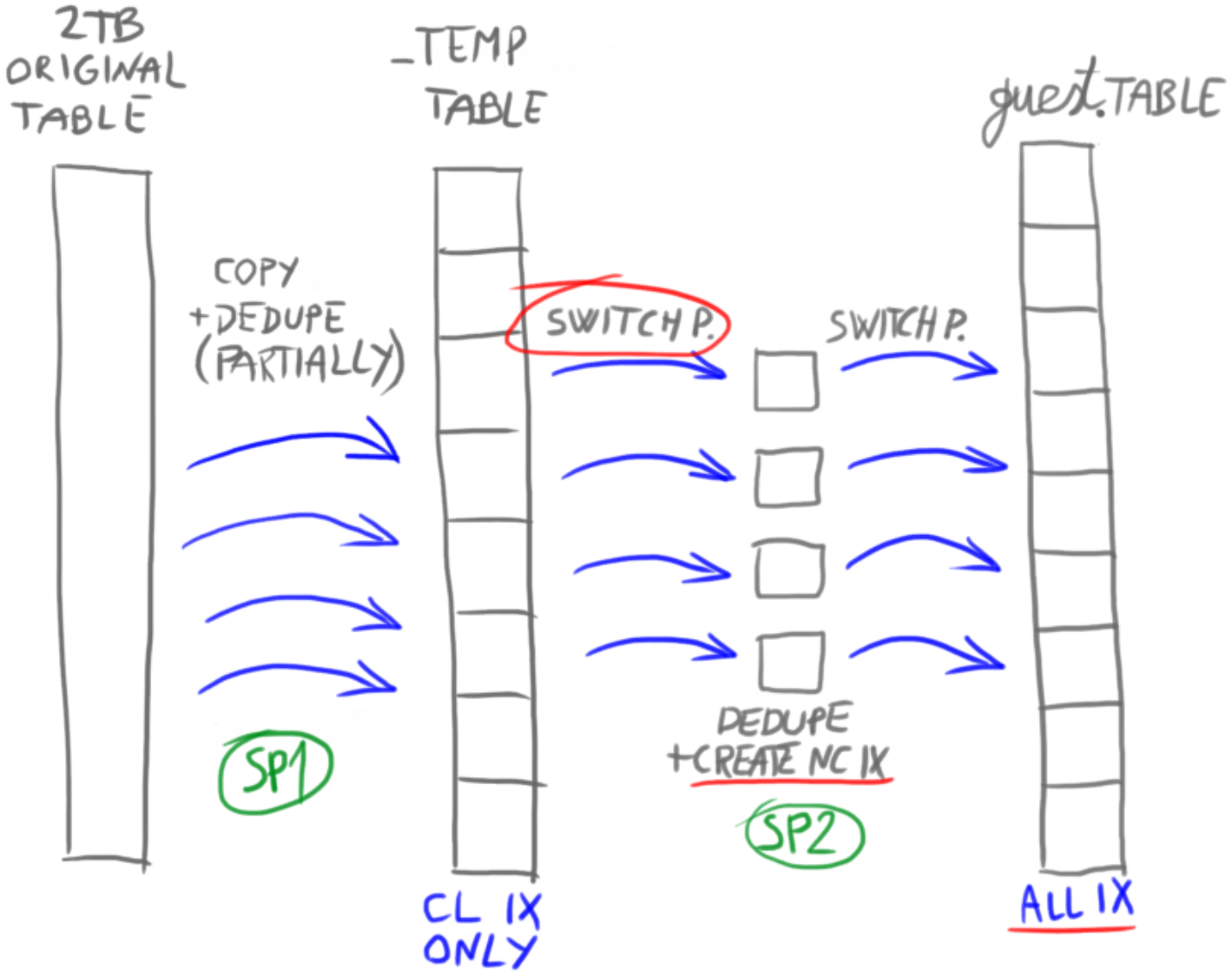
The final switch
Final destination table has the same name as original, and all constraints and indexes named the same as in original table. How is that possible, wouldn’t that procedure „name already exists“ error? Well, the final destination table was built inside the „guest“ schema. After Phase 2 finished, I moved the table into „dbo“ schema using a quick metadata operation: ALTER SCHEMA TRANSFER.
But wait, what about new rows coming in?
This table receives only INSERT and SELECT commands. That enabled us to easily detect new rows by saving the max identity value before starting the process. If table had UPDATE/DELETE I would use a different technique (Change Tracking, Change Data Capture) with the same simple purpose – to sync only rows that are inserted (or maybe upd/del) into original table while the process was running. Before the final switch, we run a „delta copy“ that takes only newly inserted rows and copies them into the final table in the guest schema. Then we X-lock the original table to prevent any modifications, do a delta copy again (which is now super-fast because in this short time only small number of changes occured), switch the table from guest into dbo schema, and release the X lock by COMMIT-ing the transaction. This is a very fast (short) transaction, blocking users maybe for 1 second, and they do not notice at all. Users percieve it as a complete online operation, without any downtime.
Conclusion
In total, we created 2 stored procedures, 12 SQL jobs, and 2 partitioned tables. Entire processing took only 2.5h to finish and less than 1TB of extra space during the move.
It is possible for an experienced DBA (a certified SQL Master to be exact 😊) to create a super-fast transition of a big table into a partitioned structure, by knowing internals of SQL server and leveraging multiple techniques. Table became faster for some queries, and more manageable. Automatic sliding window of monthly partitions will be soon implemented via jobs that automatically create new partitions and archive the old ones. It is already done, in testing phase.
This is super cool!
Thanks for sharing.
Best Regards
Hemantgiri