
Query with optional filters (catch-all query)
Introduction
Filtering the same data with different (dynamic) filters? We call that a set of “optional filters” attached to a query, usually using “OR” to enable/disable certain filters. SQL performs poorly for that situation because a query optimizer builds only ONE plan that will handle every filter combination you throw at it. For example, we have index on NAME and another index on ID column. If compiled plan goes by NAME it is not efficient to reuse when we execute it with filter on ID in the next call, isn’t it? We get the plan that is occasionally slow, and looks like a random performance problem, giving a headache to DBAs. It depends on parameter values that proc was executed with while it was (re)compiled. And we do not want our systems to depend on luck or random stuff, right? Make it run fast by adding only filters that we use. That will give us the best possible performance and consistent response time, without random slowness that drains DBA’s time, company’s money and user’s nervs. How? Read on…
The setup
We will create one table with different indexes to support different filtering criteria: by id, and by name.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
-- THE SETUP USE tempdb; -- Create TABLE IF OBJECT_ID('dbo.objects') IS NOT NULL DROP TABLE dbo.objects; SELECT schema_name = s.name, o.name, o.object_id, o.modify_date INTO dbo.objects FROM sys.all_objects o JOIN sys.schemas s ON o.schema_id = s.schema_id GO -- Create INDEXES CREATE INDEX objects_IX_name ON dbo.objects(name); CREATE INDEX objects_IX_id ON dbo.objects(object_id); |
“OR” – a typical (bad) solution
People typically solve optional filters with a procedure that involves bunch of “(@param IS NULL OR field=@param)” phrases, like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
-- The "usual" solution - not very efficient! Causes occasional slowness. IF OBJECT_ID('dbo.ObjectGet') IS NULL EXEC('CREATE PROCEDURE dbo.ObjectGet AS SELECT NULL'); GO ALTER PROCEDURE dbo.ObjectGet ( @name nvarchar(200) = NULL, @object_id int = NULL ) AS BEGIN SELECT o.schema_name, o.name, o.object_id, o.modify_date FROM dbo.objects o WHERE (@name IS NULL OR o.name LIKE @name) AND (@object_id IS NULL OR o.object_id = @object_id) --OPTION (QUERYTRACEON 9130) -- to see separate FILTER operator in execution plan END GO |
The problem with this solution is – it creates only one plan. Depending on what was the first call, what parameter values were during a compile, the generated plan will use one index or the other index. Then it caches the plan in the plan cache and uses that plan for all subsequent executions, even if they are with completely different filtering condition – and that is very wrong, very bad for performance. We use “sp_recompile” to delete the plan from the plan cache, to simulate first execution or execution after stats changed (recompile):
|
1 2 3 4 5 6 7 8 9 10 11 |
-- Test1: Both calls SCAN index on object_id exec sys.sp_recompile 'dbo.ObjectGet'; EXEC dbo.ObjectGet @object_id=3 EXEC dbo.ObjectGet @name='tables' GO -- Test2: Both calls SCAN index on name exec sys.sp_recompile 'dbo.ObjectGet'; EXEC dbo.ObjectGet @name='tables' EXEC dbo.ObjectGet @object_id=3 GO |
And the actual execution plans for all 4 executions:
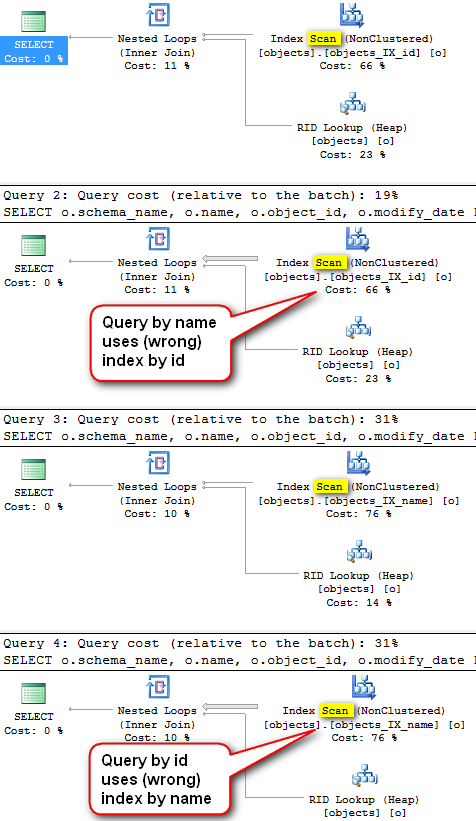
One would expect that search by name will use index by name, and search by object id would use index on object_id. But that is NOT the case! Because we only have one plan, and that one cannot fit all (filtering conditions). We should have one plan for name filter and the other plan for object id filter. That is – one plan per every combination of filtering parameters that are executed. And do not be afraid of lots of plans in the cache – usually it is quite a low number of combinations that are actually used, only a subset of possible combinations often resulting in just a few plans, exactly the ones we actually need.
Also, notice the SCAN operator. Index seek would be preferred here, but optimizer must cover a situation where filter is NULL with only one plan, and it decides on index scan, which is another bad thing we will fix here.
Other solution attempts (that do not work)
OPTION(OPTIMIZE FOR UNKNOWN) hint will not solve this, because it will create only one plan. And one plan cannot fit all filters that require access through different indexes.
IF branch into two similar statements with different WHERE clause – although each statement has a separate plan, that will also not solve the issue. Because the plan for the whole procedure with both statements is created on first procedure execution. Even the statement that is in IF branch which is NOT executed, will have a plan created on first execution of the procedure. And that plan will have wrong parameter values to lookup statistics histograms with, and it is likely to generate suboptimal plans. And another problem is that we must cover all combinations of similar statements, and with many filtering columns that can be considerable number of statements, very cumbersome, copy-pasted code to 10+ if branches that all look similar and is a nightmare to support.
RECOMPILE query hint can have different plan per every execution, should get us good plans. But the problem is that the query will not be cached, we will be unable to track its statistics in DMVs, which is not good. However, it will contribute to execution statistics of parent procedure the statement is within. Also, we will have a recompile on every execution, which takes CPU and compile locks – not good for concurrency and CPU. Recompile hint might be used temporarily to confirm that different plan will resolve the issue, but should not be there to stay, especially for something that is frequently executed, or query that is normally fast and compile overhead takes considerable percentage of compile+execution time.
Solution – use Dynamic SQL for multiple plans
Good path to go is dynamic SQL. A colleague MCM Gail Shaw wrote a blog post about it, long time ago. But here we will go further, and improve the technique.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
IF OBJECT_ID('dbo.ObjectGet') IS NULL EXEC('CREATE PROCEDURE dbo.ObjectGet AS SELECT NULL'); GO ALTER PROCEDURE dbo.ObjectGet ( @name nvarchar(200) = NULL, @object_id int = NULL ) AS BEGIN -- Note: there is NO "+" sign. We have single, monolithic, multiline SQL without any concatenation! DECLARE @sql NVARCHAR(4000) = ' SELECT o.schema_name, o.name, o.object_id, o.modify_date FROM dbo.objects o WHERE 1=1 --NAME--AND o.name LIKE @name --OBJECT_ID--AND o.object_id = @object_id'; -- Lets uncomment only filters we need IF @name is not null SET @sql = REPLACE(@sql, '--NAME--', ''); IF @object_id is not null SET @sql = REPLACE(@sql, '--OBJECT_ID--', ''); -- Execute. Note: values are sent as parameters. We send all params, even only some (or none) are actually used. exec sys.sp_executesql @sql, N'@name nvarchar(200), @object_id int', -- parameters declaration @name, @object_id -- values for parameters END GO -- Test! EXEC dbo.ObjectGet @object_id=3 -- used index by object_id EXEC dbo.ObjectGet @name='tables' -- used index by name EXEC dbo.ObjectGet -- all rows - SCAN |
Note that we do not have concatenation (+) anywhere! We have commented parts and remove the comment mark later in the code with REPLACE command to make that filter effective. The advantage is that not only it is simpler to write without “+”, and we can copy-paste into SQL editor and tun with almost no changes, but also we can comment-out JOIN clause and filter with the same keyword, thus with one switch eliminate even tables used for filtering and whole subqueries, not only WHERE condition.
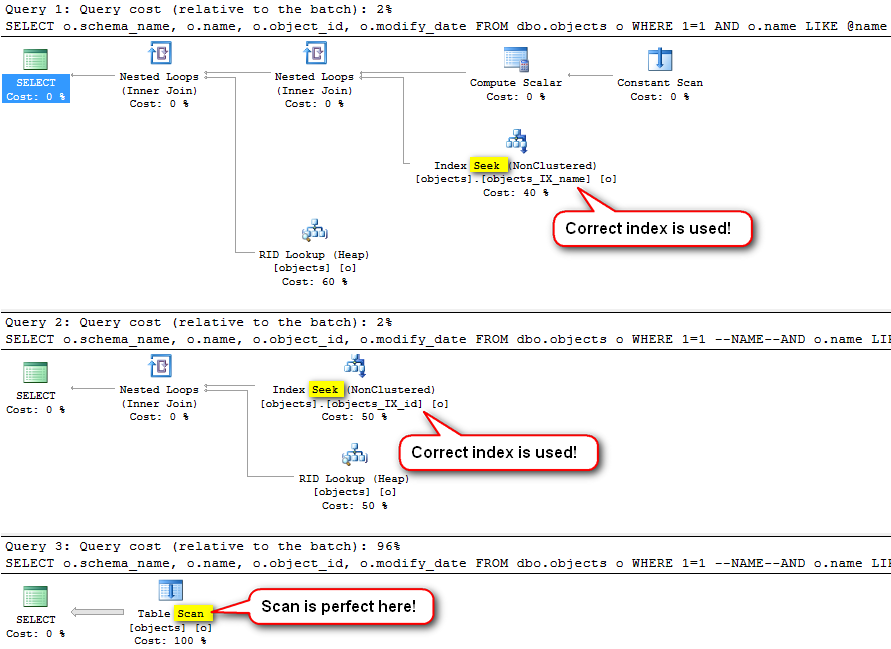
Note we got 3 different execution plans. Every time ideal plan is used for every filtering condition: index on name for filter by name, index on onject_id for filter on object_id and full table scan for case without filter.
Optional BLOCKS of code (multi-liner filters)
If your filter is not one-liner, but something complex, a join, subquery, anything with multiple lines – this is a handy trick to set it as optional filter. Surround that block of code with a block comment with a special mark, eg “/*FILTER_WITH_MANY_LINES” and “–*/” at the end. Then if filtering is specified, you enable that block of code with REPLACE, like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
DECLARE @sql NVARCHAR(1000) =' /*REMOVE_TURNS_BLOCK_ON-- SELECT 123 --*/ --REMOVE_TURNS_BLOCK_OFF/* SELECT 123 --*/ '; print @sql -- before SET @sql=REPLACE(@sql, '/*REMOVE_TURNS_BLOCK_ON--', '') -- turn ON SET @sql=REPLACE(@sql, '--REMOVE_TURNS_BLOCK_OFF', '') -- turn OFF print @sql -- after |
The result, before/after:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
/*REMOVE_TURNS_BLOCK_ON-- SELECT 123 --*/ --REMOVE_TURNS_BLOCK_OFF/* SELECT 123 --*/ SELECT 123 --*/ /* SELECT 123 --*/ |
You can have multiple blocks with the same marking keyword, and this will work.
Handling skewed values
If we have highly skewed values in column we are filtering on, that can also give us an sub-optimal plan, and performance problems that occurs occasionally. Because the plan is built based on one value, and not on the other. For example, you might have many rows in “processed” state, and only few rows in “not processed”. For “not processed” we should use index, and for “processed” full scan will be much faster than index. Or, you might have a multi-tenant database. Some tenants are very big (have lot’s of rows), and others are small. The query plan that is good for small tenant might not be optimal for small tenant and vice versa. Therefore we need two plans, even though filtering condition looks the same. The only difference is ID of the tenant, a value of the filter. A respected colleague MCM Kimberly L. Tripp from sqlskills.com presents a targeted RECOMPILE hint solution in blog post Building High Performance Stored Procedures. That works, but we will go a step further and improve it, we will make a solution without recompile.
We will achieve two plans for the same statement by adding an innocent change to our dynamic SQL command: a comment! Although looks innocent, that will create two execution plans: one for statement that has a comment and without a comment, and they are potentially different and can use different indexes. Sometimes the optimal solution will use the same indexes and both plans will be the same, but now optimizer at least has a chance to build a different, hopefully better plan. The difficulty here is to recognize do we have an id of a big tenant or not? Lucky for us, really big ones are rare. There are bunch of small ones, and only few big ones. Because, if we would have a lot of big ones, they would become average ones. Therefore it is impossible to have a lot of big ones. We should have a list of super-big tenant ids somewhere. The best would be in a table, or hard-coded in a common place like a function, so no code change is needed when adding new big tenant id.
COMPLETE SOLUTION
This solution can use different indexes for different set of parameters, and handles skewed values without RECOMPILE hint:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
-- Create skewness INSERT INTO dbo.objects SELECT 'big', 'tenant', object_id=111, modify_date FROM dbo.objects o GO 5 -- Create procedure IF OBJECT_ID('dbo.ObjectGet') IS NULL EXEC('CREATE PROCEDURE dbo.ObjectGet AS SELECT NULL'); GO ALTER PROCEDURE dbo.ObjectGet ( @name nvarchar(200) = NULL, @object_id int = NULL ) AS BEGIN -- Note: there is NO "+" sign. We have single, monolithic, multi-line SQL without any concatenation! DECLARE @sql NVARCHAR(4000) = ' SELECT o.schema_name, o.name, o.object_id, o.modify_date FROM dbo.objects o WHERE 1=1 --NAME--AND o.name LIKE @name --OBJECT_ID--AND o.object_id = @object_id'; -- Lets uncomment only filters we need IF @name is not null SET @sql = REPLACE(@sql, '--NAME--', ''); IF @object_id is not null SET @sql = REPLACE(@sql, '--OBJECT_ID--', ''); -- Big tenants. ID should be taken from config table eg "big_tenants", but here is hard-coded for brevity. IF @object_id IN (111) SET @sql += '--BIG_object_id' -- Execute. Note: values are sent as parameters. We send all the parameters, but only a subset is actually used. exec sys.sp_executesql @sql, N'@name nvarchar(200), @object_id int', -- parameters declaration @name, @object_id -- values for parameters END GO -- Test EXEC dbo.ObjectGet @name='tables' -- uses index by name EXEC dbo.ObjectGet @object_id=3 -- used index by object_id EXEC dbo.ObjectGet @object_id=111 -- used table SCAN - super! |
The only problem is – how to recognize “big” tenants automatically?
We can always enter their IDs manually into config table, but automatic process would be preferred. One automatic process that comes to my mind is to have a job that periodically counts rows of a certain table (or just the stats histogram of that table), recognizes those who have much more rows than average rows per tenant (eg. 10x more), and inserts those “big” IDs into config table or dynamically builds a common function with hard-coded “big” IDs. Why formula “10x more rows than average”? Optimizer knows the average number of rows from statistics, and will use that assumption for example when enforced with “OPTIMIZE FOR UNKNOWN” hint. But we want to catch here values that are significantly different than average, so different that they deserve a separate plan. In our example we talk about tenant id, but that can be really any column that has skewed values and we have to recognize the “big” ones. The query to fing “big” ones might look like this (run with Query->SQLCMD Mode turned ON):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
-- Use your table and column names. Enable SQLCMD mode. :SETVAR MY_TABLE "dbo.objects" :SETVAR GROUPING_COLUMN "object_id" GO select a.*, f.pct_total from ( -- get total table rows from metadata (fastest) select total_row_count = SUM(p.rows) from sys.partitions p where p.index_id in (0, 1) and p.object_id = object_id('$(MY_TABLE)') ) s CROSS JOIN ( select o.$(GROUPING_COLUMN), row_count = count(*) from $(MY_TABLE) o --<< YOUR TABLE NAME HERE group by o.$(GROUPING_COLUMN) having count(*) > 10 -- not interested in values with small number of rows ) a cross apply(select pct_total = a.row_count*100/total_row_count) f where f.pct_total >= 5 -- percent of rows with that value in all rows of the table order by pct_total DESC |
object_id row_count pct_total
———– ———– ——————–
111 70370 96
(1 row(s) affected)
When NOT to use dynamic SQL solution?
Not every case should be solved with dynamic SQL. Do not make every query dynamic without reason, without identifying that the problem is really that different plans are needed for different filters or skewness (big/small values). And even then – measure! If benefit is not noticable, do not make that plan dynamic. Dynamic code is more complicated to manage, errors are spotted only during runtime (not compile time), and there is no intellisense. Keeping that in mind, there are the cases of “catch all” queries that will probably not benefit from dynamic sql solution:
-
- Searching through small table will be fast even when scanned, and dynamic SQL would not improve the speed noticeably.
-
- If there is no index on the filtering column, then even big tables will probably not benefit from making that condition dynamically added. If we decide that column should not have an index, it is ok for such column to use the “AND (@filter IS NULL OR o.column = @filter)” pattern.
-
- queries that are always fast (don’t fix it if it is not broken!)
- queries which slowness is not caused by described problem
Conclusion
SQL generally builds only one plan per query or procedure (exceptions exist but they are for some other blog post). Therefore, “catch all” queries (those queries using optional filters in where condition) will also build only one plan which cannot be optimal for every filter combination that is thrown at the query. We must use different indexes for different filter combination, and that means different plans. That can be achieved through dynamic SQL, using commented filtering conditions, and only ones we need are commented-out. Additionally, we can detect “big” values of parameters, and force SQL to come up with a separate plan for those just by adding an ordinary comment to dynamic SQL statement, just to make the statement different to get a chance for a different plan. The result is – very fast, optimal queries for every filtering parameter combination, without RECOMPILE hint, and plans reused – perfect!
Updated query to find values with many rows – a smarter version.
Added “Optional BLOCKS of code (multi-liner filters)”